Feb 12, 2018

INTRODUCTION
The Columbia University Library recently completed a two-year project, funded by the National Endowment for the Humanities, to digitize 140,000 pages of interview documents from the Language and Culture Atlas of Ashkenazi Jewry archive. The archive, which consists of over 600 interviews conducted with native speakers of Yiddish between 1959 and 1972, was created by linguist Dr. Uriel Weinreich and continued after his death in 1967 under the directorship of Dr. Marvin Herzog. It was a comparative study of the linguistic diversity of pre-WWII Yiddish in Central and Eastern Europe.
Columbia’s recent digitization of the written data from the archive makes the digitized content freely available to scholars via the Digital Library Collections at Columbia, through a newly launched website and accompanying guide. The Libraries have reprocessed the full LCAAJ archive for scholarly use and have carried out optical character recognition (OCR) and mark-up of the printed interview responses to enable their content to be searched and manipulated. These written materials accompany more than 5,700 hours of audio recorded interviews that Columbia Libraries has already digitized through generous support from NEH, private foundations, the New York State Conservation/Preservation Program, and Evidence of Yiddish Documented in European Societies (EYDES, a project of the German Förderverein für Jiddische Sprache und Kultur), through which the audio is publicly available. Their long-term goal is to eventually link the written content to the audio recordings of the interviews and make the entire audio and written corpus available to students and scholars in an integrated form.
As part of the launch of the project, an exhibition called “Yiddish at Columbia” will be mounted in the Chang Octagon Gallery in the Rare Book & Manuscript Library at Columbia University in early March.
I discussed the project with Michelle Chesner, Norman E. Alexander Librarian for Jewish Studies at Columbia University.
Jessica Kirzane: What are the goals of the LCAAJ Project?
Michelle Chesner: The goal was to trace dialectical differences in Yiddish, based on geographical location. Sort of the anti-YIVO, trying to—and not aggressively, but—trying to show how Yiddish is a hugely multifaceted language and different people spoke it completely differently. They wanted to hear what the difference was from Yiddish in Łódź to Yiddish in Warsaw to Yiddish in Krakow to Yiddish in Berlin, such that it was. And so, they compiled a questionnaire that was about 2500 questions for what they called the Eastern Questionnaire, which covered Eastern Europe. They asked subjects questions around basic topics, so for instance, “the village and its environs,” “the body,” “dress,” “house,” and on and on. But really what they were listening for was, for example, glottal stops, or answers to very technical linguistic questions. They also explored different terms that were being used, so it was almost a parallel to the Yiddish dictionary, in a way, of all the varieties of spoken Yiddish. The interviews for the Eastern Questionnaire were about sixteen hours each, so really extensive interviews, and six hundred people were interviewed. There was also a Western Questionnaire that was much shorter. It was appended to the Eastern Questionnaire, and the questions were asked in German or French, rather than in Yiddish. And this was to get into the languages that to a Yiddish purist are not Yiddish, like Judeo-Alsacien, or even Judeo-German, or some of these Jewish vernaculars that were close to Yiddish . . . but they weren’t Yiddish to somebody who studied Yiddish as a language formally. So the Western questionnaire was its own piece.
They were collecting all this data for LCAAJ at a time when Yiddish speakers, that variety of native Yiddish speakers, they were dying. The fact of the matter is that native Yiddish speakers now exist in very specific enclaves and a lot of those varieties of Yiddish are gone. They were at a critical point and they collected data, both audio and written, that can no longer be collected today, and that’s huge. And they applied to the National Institute of Health and got money for it. Their original funds were from science foundations, and one of the things that they talked about was that a doctor could speak to his Yiddish-speaking patient. In an immigrant era where there were many people for whom Yiddish was their native language--if a doctor wanted to understand what the problem was--then broken English wasn’t going to help, so they needed to know what the Yiddish words were for whatever body part or feeling, and that was part of the argument the project directors made in applying for funds. Andrew Sunshine actually wrote a couple of articles about some of the early motivations for the project and it’s just really interesting because it’s a totally different perspective than we might have about it today.
JK: It sounds like a lot of information to organize.
MC: it was a huge, huge, data project. And they were doing it with computers as early as 1961. I’ve been trying to say this was an early Digital Humanities project. They were involved with the Columbia Center for Computing, which was one of the first places to get those big wall computers. They had punch cards and they were inputting the data into the computer. There were two ways that they recorded the responses. There was the audio—that was the full audio of the questions and the answers—and there was the written portion, which was just the specific word that they wanted. So, for instance, if I ask you what the word is for the bread that you eat on Shabes, you might say, “Oh, and by the way I have a great challah recipe!” You might just go off on a tangent a little bit, but in the written portion they just took the word challah. Whereas the audio includes all of the social history around it. So the audio was actually digitized in the ‘90s. Again, very, very cutting edge for its time.
JK: What did digitization mean at that time?
MC: The tapes were both digitized and preserved. We have preservation copies that are not digital, because digitization was brand new. It’s digitized in that you can go to the website of EYDES and you can listen to digital audio files. 1 1 The LCAAJ archive was deposited in the Columbia Library when the Linguistic Department effectively was closed and there could be no more work done at Columbia on the LCAAJ (a broader history of the archive at Columbia can be found here.) For a while people could still go to what’s now the Said Reading Room to use the materials of the Atlas. The project nevertheless continued in a formal academic context in Germany at EYDES, or Evidence of Yiddish Documented in European Societies, run out of Düsseldorf under the aegis of the Förderverein für Jiddische Sprache und Kultur. EYDES also has created a downloadable Repository with the audio files for use on one's own computer. The Repository includes tools for mixing and matching of the sound segments.
JK: Originally the recordings were recorded on tapes?
MC: Reel to reel tapes, yes, in different formats. The interviews were primarily recorded in the ‘50s to the ‘70s. And then after that they started doing research with the data. What we have, in addition to the digitized files, are preservation standard reel-to-reel copies, so if someone wants a redigitization, they want audio files that they can work with in 2018, they can come to us and we can have them transferred to digital.
JK: So the tapes were digitized in partnership with EYDES already. What was the digitization project Columbia Libraries just completed?
MC: In addition to the audio recordings of the interviews, the interviewers wrote down the specific answer, just a word or phrase, that was being sought by each of the questions. So, in the example I gave before, the audio gives the whole challah recipe, and the answer sheet has just the word, challah, transcribed as it was pronounced. At first they started writing those down just in blue books, like what you would write your final exam in, because that was what they had. But they standardized it fairly early, and they produced answer sheets. So, for instance, every page 72 has answers to the same questions. So if you’re interested in a particular linguistic concept that’s represented by a word that’s on page 72, you could pull up all the page 72s in the entire project and look up the answer to that question. But of course looking up data on a single word manually would be enormously time consuming. You’d have to look at every single page 72 from every single folder, and that would take hours and hours. So they entered edited versions of much of the data in four separate batches into a computer and printed out the results, arranged by question number, so you could look at just question number 57 on page 72, and you could have a lot of it right in front of you.
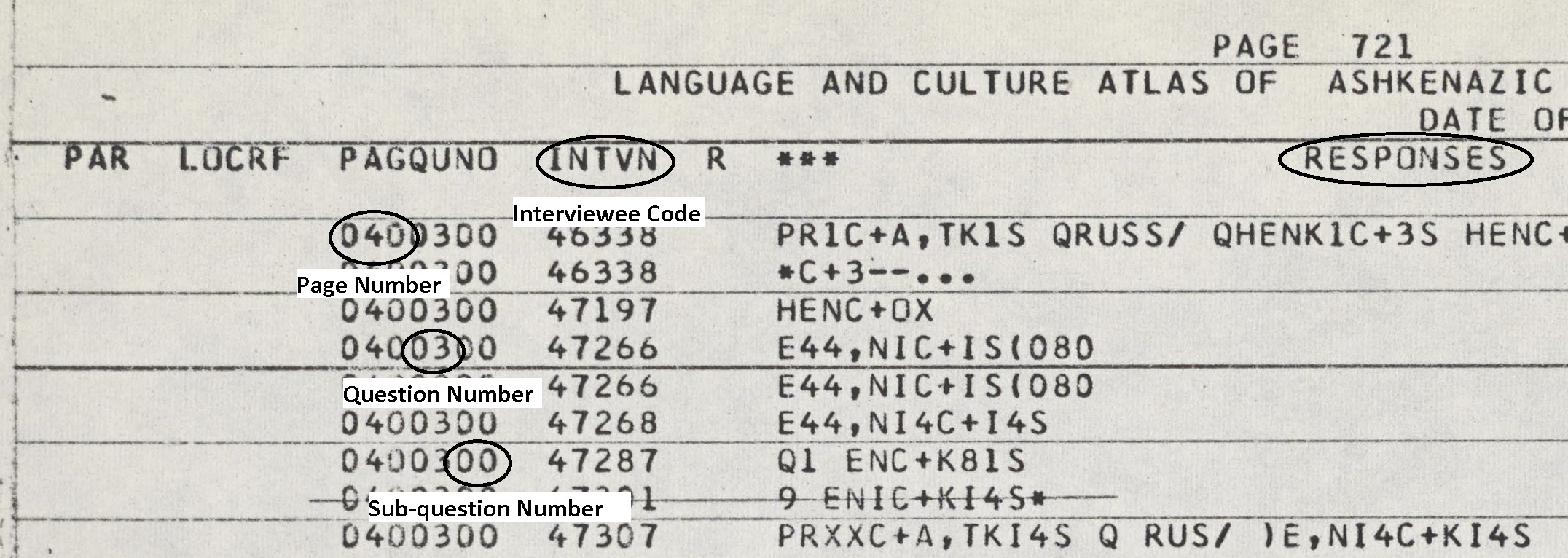
Example of an LCAAJ printout
What we did was to digitize the responses. We called the project “Digitizing the Data.” We have the entire archive of the collection which is over two hundred boxes, including the answer sheets and printouts, hand drawn maps, correspondence, research material, documentation, and much, much more. Sandra Chiritescu spent two years reprocessing it, so it’s now available in a way that makes sense to users. I have to say that Andrew Sunshine did a preliminary inventory when the archive was first moved to the library and it’s the only reason we can make any sense of it. But what Sandra did was to organize the archive into an order that made sense intellectually. Basically [the project members were] told that they had to clear out the space, and they emptied their file cabinets into boxes, and whatever they had been using at that moment was what appears in the first boxes. It was a mess. So the idea is that people can now access and use the data much more easily. The way that the archive was until now, since it entered the library, was that the archive was sort of catalogued, it was offsite, but you had to know exactly what you were looking for in order to request it. You had to be very familiar with the project, and you had to come to Columbia to conduct your research. We did have users who came who were working in linguistics and knew precisely what specific area they were interested in. But with digitization, scholars don’t have to sit in a reading room and look at the physical materials; they can look at it online.
In addition to this digitization, we also have a project to make some of the material searchable. This is still in progress. We had to sort of reverse-engineer it. We didn’t have the original punch cards or files for what they had entered into the computer to create aggregated printouts for single questions from answer sheets. The answer sheets are all handwritten, and that’s very hard to put through OCR. But we were able to put the printouts through OCR. This took a little bit of machine training and a lot of work.
Ultimately we want to integrate all the data and have everything searchable in one place. The extent of phase one was to digitize the Blue Books, the answer sheets, and the printouts, and to OCR the printouts, and that’s what’s online right now. So the website dlc.library.columbia.edu/LCAAJ provides access to the 100,000-plus images of the digitized blue books, answer sheets, and printouts, and guides.library.columbia.edu/LCAAJ provides all of the background information, a lot of pdfs of supplemental material, the transcription guide--it’s basically a user’s guide with everything else that you would need to know, so they really work in tandem.
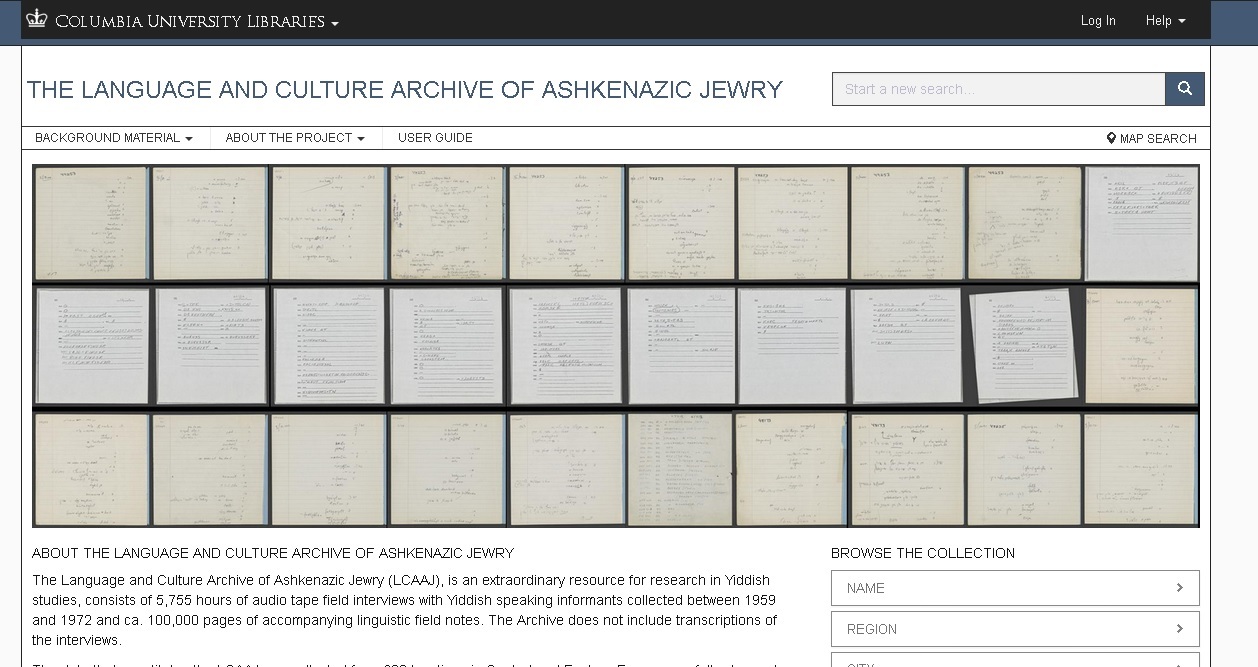
The new LCAAJ homepage
JK: So what are the next steps for all of this?
MC: What we would like is for this work to be done collaboratively. So if you are working within a particular geographical area, on a subset of questions, and you are working with the answer sheets, you likely have to be transcribing answers from what you are seeing in the images. We would love for you to transcribe that into a shared Google spreadsheet that we have set up, so that when you’re doing the work of transcription anyway, it will be accessible to other people. The idea is that there are many people who are doing this work, and nobody should be doing it in isolation. We understand that from a scholarly perspective there is a concern about other people scooping your work and we respect that, but to the extent possible if this could be done in a collaborative manner, it would be value added for everybody. Ultimately everybody could win. And if that means maybe wait until your research has been published and then give us your transcriptions, that’s fine, we’re willing to wait, but really the idea is that the more people give, the more everybody else will get. That can be hard to understand for some people, but I come from a library world where open access and open source is a given, so we hope that will happen in other contexts.
JK: Do you think this material could be used in a classroom?
MC: I requested—and the conservation department digitized—one complete audio file of an interview for me because I am really interested in how it can be used in the classroom to teach Yiddish. And the audio is just audio of two people talking in Yiddish, answering questions and asking questions. I am interested in thinking about how that could be used in a Yiddish language classroom. How that could be used in a Yiddish III course could be really interesting. I also have ulterior motives, because there’s more that we want to do and I feel like it could be an assignment that’s given to students so that they could learn from it but also help. We’d like to break down the audio by question, so that if you’re interested in number twenty-five on page 15 you can just skip to the audio, and that can’t be done right now because it’s so vast that it has to be manually broken down. And that’s something that can be done very long term while having students hear authentic spoken Yiddish, but also helping us. So that’s also an idea I’ve been toying with.
JK: I know it’s early, but are scholars using this digitized material right now?
MC: One researcher using this data is Lea Schäfer who is working on a project called Syntax of Eastern Yiddish Dialects (SEYD). She’s a postdoc who’s doing really interesting work in a digital environment. I like to think that Lea is using the Atlas in the way that Uriel Weinreich envisioned it. We actually gave her access to the digitized materials as soon as they were available, before the website even went live, because she wrote to us asking for it. And she’s done some beautiful maps already. It’s just a great example of how, as soon as the data was available it was used. And so we’ve been talking with other people, with other scholars, who are interested in using the data in different ways. And we want to be as open as possible to facilitate conversations wherever we can, and to give people whatever they want, to the extent that it’s possible. We’re not able to promise technological enhancements because that takes time and money, but whatever we already have we want to make available.
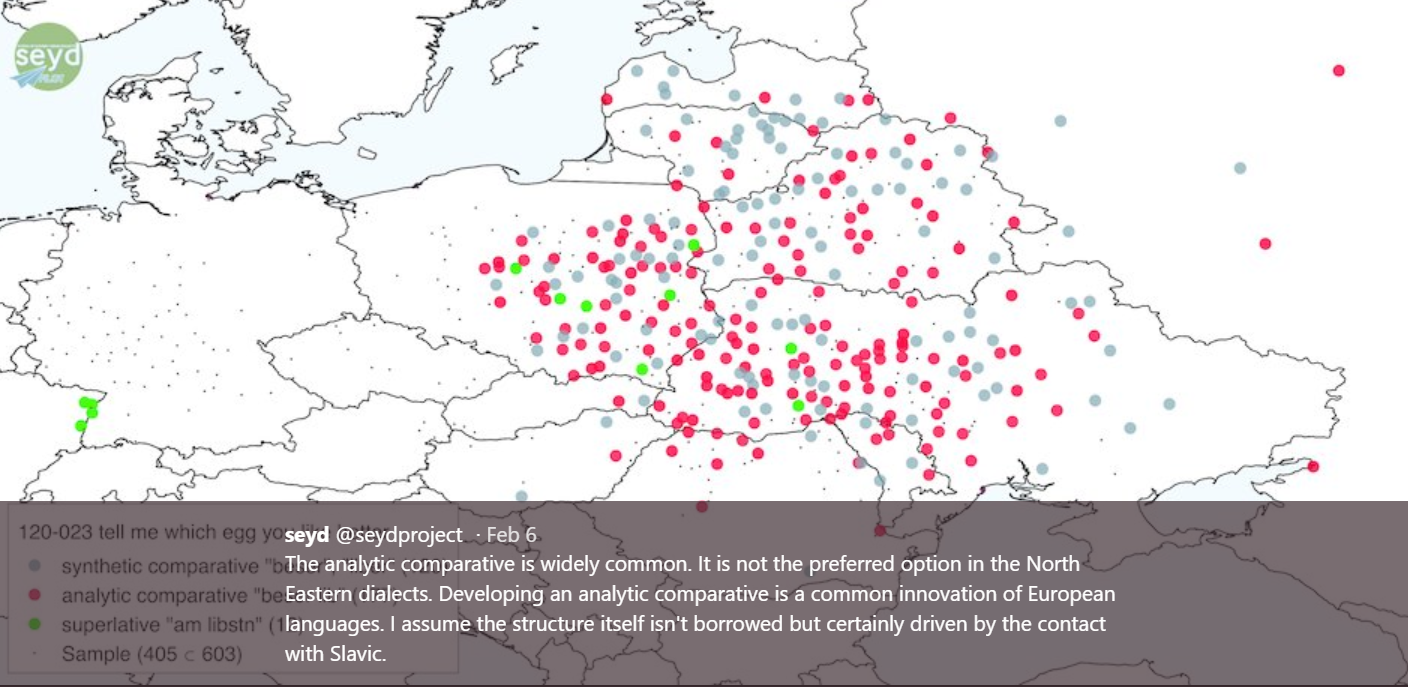
example map from SEYD
JK: Do you have a background in Yiddish?
MC: My original learning of Yiddish was that it was the language my parents spoke when they didn’t want me to understand, so it’s more native-ish than formal. And then as I moved forward in my life and career I’ve done some more.
JK: Has working with this project changed your relationship to Yiddish and how you think about Yiddish and its varieties?
MC: I come from a background where the Yiddish that I heard was a Lithuanian, very Litvak Yiddish, and yet it’s pronounced differently than YIVO Yiddish that I’ve heard spoken. I can understand that confusion of people who learn Yiddish in college and then go to talk to their grandparents in Yiddish and their grandparents don’t understand them. I think that for some people that would make me an outsider because I don’t have the YIVO training. But that perspective is what makes me like this project so much. What YIVO did—and they needed to—was to impose structure. In order to teach a language you need structure. But they invented a language, in a way. It’s ironic that Max Weinreich’s son was the one to do this; the father is imposing structure on the language, and the son is focusing on the variety. I think it’s critical that we maintain this knowledge through this data that we have of all of the differences, of the rainbow of Yiddish that existed, even if it’s not as diverse today.
JK: Can you tell me about your exhibit?
MC: The exhibit is directly because of the LCAAJ. Part of our agreement when we got the grant from the NEH is that we were going to promote it and share it. And it’s also a way for me to go back to a place where I’m comfortable, which is the Columbia collection, where I spend a lot of my time and find all sorts of amazing things. The exhibit is in a small gallery, the Chang Octagon Gallery in the Rare Book and Manuscript Library. It has six cases. For me this was a way to highlight Columbia’s glorious history of Yiddish and also the Yiddish in Columbia’s collections. You read Aaron Lansky’s book and you think nobody cared about Yiddish anywhere, but actually we have all those books. They might not be well catalogued—we’re working on it—but we have Yiddish collections that were just coming in during the very years when people think no one cared about Yiddish. All of this stuff that Aaron Lansky talks about people not caring about, we had here because it was important for scholarship. Because the work was being done at Columbia. But also we had historic collections. Because our special collections are so vast and broad, I stumble across things, and as part of my job I buy rare materials, and Yiddish is one of the things I focus on because of what we have in the collection and to support the work that’s being done.

Sefer Refu’os u’Segulos (Book of Remedies and Incantations), fifteenth century Italian manuscript featured in the “Yiddish at Columbia” exhibit in the Chang Octagon Gallery in the Rare Book & Manuscript Library at Columbia University in early March.
So there are six cases. The first is Old Yiddish materials. I have this medical manuscript, a fifteenth century northern Italian medical manuscript in Yiddish which has all kinds of fascinating potions and incantations and it basically crosses any discipline that you’d want to go into, but the language is mostly Yiddish. Then I have some early Yiddish imprints, so one of them is a Mishle printed in Krakow in 1582, if I recall correctly, and it’s beautiful. It has a lovely woodcut and then the text of Mishle in this distinctive type (originated in Prague), and then with Yiddish translation in Vaybertaytsh font to accompany it. Then I have a Dutch translation of the Bible into Yiddish, and an Artushof—King Arthur in Yiddish, and a handwritten letter in Yiddish from the eighteenth century. The next case is about ritual: tkhines, a guide to funeral rites written in Judeo-Alsatian, and a Sefer Minhagim, the first Sefer Minhagim to be printed in Yiddish. The next case is on Yiddish theater, so we jump into the modern era. I have an Avrom Goldfaden manuscript with three plays, and a poster from Zosa Szajkowski: he had these huge posters from France of Yiddish performances, so there’s this beautiful poster that’s going to be there. 2 2 Szajkowski was infamous for his thefts of historical material from French archives, as detailed by Lisa Leff in The archive thief : the man who salvaged French Jewish history in the wake of the Holocaust (New York: Oxford University Press, 2015) I have some photo albums of the Bergen-Belsen Theater Troupe, which was in the DP camp at Bergen-Belsen. The next case is on Yiddish Press: we have these political cartoons including one by Art Young with Yiddish captions. He pasted English labels over his Yiddish captions so he could use it again in an English-speaking context. Then we have one by William Gropper about the Nuremberg Trials, called International Justice, and then copies of In zikh, because it was such an important publication for Yiddish literature. Then the last case is on Academic Yiddish, which is mostly about Yiddish at Columbia. Thanks to Sonia Gollance’s post from the Digital Yiddish Theater Archive about playwright David Pinski attending Columbia, I was able to track down a copy of David Pinski’s enrollment records. We have the deed of gift for the Atran professorship for Yiddish Language and Literature, 3 3 In 1952 the Atran Foundation endowed a chair for the study of the Yiddish Language, Literature, and Culture at Columbia University. It was the first chair in Yiddish Studies at an American University. The chair was held by Uriel Weinreich and Marvin Herzog, and is currently held by Jeremy Dauber. and then we have a lovely cartoon of Madam Yiddish and her Escort that was published in the Morgn zhurnal after the Atran professorship was announced in 1952. And then there’s LCAAJ: there will be an example of a Blue Book, and then an answer sheet, and then a map, to see how it was actually used, and then just some of the props that they used when they were asking questions. So there’s this brown fabric that they sewed on various kinds of buttons and clasps, so they could say to the person “what is this?” I just saw that the Forverts posted an article about terms for berries in Yiddish. The LCAAJ had a picture on a piece of cardboard of various types of berries, berries in Yiddish are interesting because the idea of what is a “blue” or “black” berry differs across cultures and geography, so they wanted to know what words people used. So, a bunch of things from the archives. Some punch cards, because that’s fun, and then a letter from the Center for Computing from the ‘60s. So the exhibit is really from Old to New, just trying to give an overview of all the different uses of Yiddish.

“Madame Yiddish and Her Escort.” This cartoon printed in Morgn-zhurnal on March 16, 1952, celebrating the establishment of the Atran Chair in Yiddish Language, Literature, and Culture, depicts philanthropist Frank Atran escorting “Yiddish” up the steps of Columbia University. It is included in the “Yiddish at Columbia” exhibit.
JK: Who is your hoped-for audience for this?
MC: It’s always a question, especially in the RBML because it’s hard to get there. One aim is to highlight the legacy of Yiddish at Columbia. One of the pieces in the collection is a full spread from Columbia College Today from the 1970s called “An Old-New Language.” In 1970 Yiddish was being taught at Columbia and there were so many people taking those classes and it was so interesting to students. And this is something that people don’t really think about now. So in a way, the exhibit is for the Columbia community. There are people who have expressed interest in the exhibit and are going to want to come and see it. But I think much of the idea behind it is for Columbia to know what was here, what was the history, for students to see what Yiddish looked like. For non-Yiddish scholars to see how vibrant the study of Yiddish can be.
JK: Can you tell me a bit about how your work with the LCAAJ project fits into the broader scope of digital humanities? I know you are a major proponent of digital humanities in Jewish Studies.
MC: Sure. Jewish Studies is by nature interdisciplinary, and I think should be collaborative. So, digitization is extraordinarily useful because of the way that Judaica collections have been scattered around the world. Even if you aren’t thinking about books, which have been scattered around the world, but archives as well. Look at the YIVO story, look at the cache that was just discovered in Lithuania. Often you have half a collection here and half a collection there, if you’re lucky. These collections are just all over the place and the natural way to put them back together again is digitally. The example I give with Footprints, a digital humanities initiative I co-direct that traces the history and movements of Jewish books during and after the early modern period, is that there was a big collection that was sold in two parts in the 1860s. Half of it went to the British Library and half of it went to Columbia. Columbia’s not giving the British Library our half and the British Library’s not giving us their half. And we would never expect them to. But the fact of the matter is that this was once one collection. So how do we conceptually reunite this collection, so you can get a picture of what it is? In the most simplistic sense, digitizing (or in this case, collecting data in a digital format) can do that. You can have access to anything anywhere if it’s digitized. But LCAAJ takes it to the next level. LCAAJ was a digital humanities project before its time. They were physically plotting locations of words and sounds on maps. We have something like twenty thick boxes filled to the brim with maps. And that’s something that’s naturally so much easier in the digital context. We can geocode it; we know the lat/longs of every interviewee. We can say here’s the data, and here’s the location on the map. It’s something that’s done so much more easily in the digital context. And then searching it will be so much easier too. Of course there will need to be more work here because it’s not all OCR-ed, only one section of it is OCR-ed at this point, but we hope to be able to make all of the data available just via search. But again, it was a computer project before its time. Had the project been done just twenty years later it would have been so easy to input all of the data and work with it. We’re talking about big data—100,000 images, and the responses—probably in the millions of actual data points. When you put that into a computer you can do exponentially so much more than what you could do before digitization. They did a tremendous amount of scholarship by hand and once it’s computed as much as we want it to be it could revolutionize the study of Yiddish. Beyond glottal stops. Does it mean that the way Yiddish is taught, the way Yiddish is approached can be different? When you read Yiddish literature can you learn something more about the author based on the language, the words that they use? There are so many different applications, some of which we don’t even know yet. Once you make the data available, you can start thinking of new ways of doing the research. So that’s one of the things about DH more broadly is that it can, it changes, it creates new questions that would never have been asked before. And that’s what I think is so interesting. Because, from a historical perspective there’s a linear way of thinking about how things happen, but when you add more elements that were never there before you can start to ask different questions.

In 1961 and 1962, Uriel Weinreich received grants from the American Philosophical Society to “explore the possibilities of utilizing data-processing machinery for the storage, filing, sorting, and searching of the accumulating field materials of the atlas.” Chesner explains that already in 1961 LCAAJ was a Digital Humanities project.
JK: Is there anything else that you want the In geveb readership to know about the project?
MC: We hope that this is just a beginning. And, you know, a lot of the ideas that we have will require funding, so we are interested in those kinds of opportunities, but we also need collaboration from scholars. In order to get anything done, especially when funding is required, you need to prove that the project is useful. So if we know who is working with this material, who is using it, and what can be made better, within reason, that helps us. We can potentially go to a donor or a foundation and say we have 500 people who are actively engaged in this, or even fifty people who are actively doing research, and these are needs that we have identified. That’s where we can bring it to phase two and broaden it out. So if people are working with, or are planning on working with this material, and especially if there are people who are doing different things that we didn’t anticipate, we want to hear from them, and we want to try to make this as usable as possible and to grow it where we can.