Sep 06, 2015
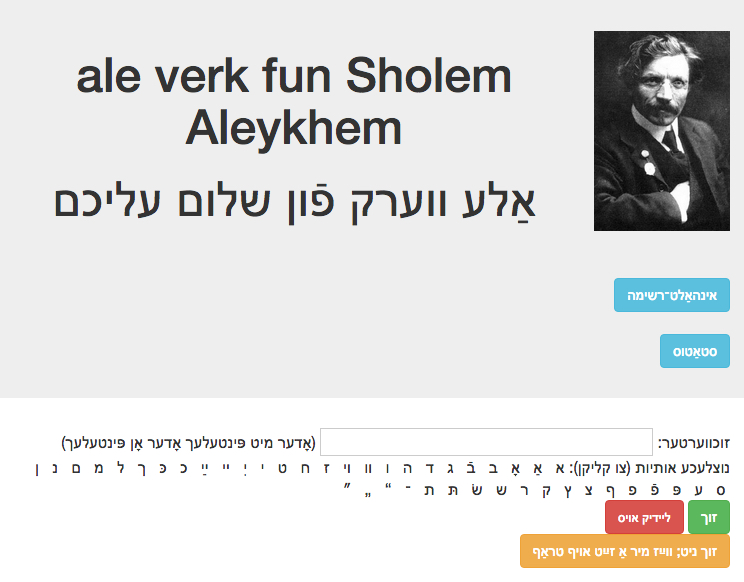
The search page for the digitized complete works of Sholem Aleichem.
Refoyl Finkel is a professor of computer science at the University of Kentucky. For many years, he has devoted much of his energy and free time to creating an OCR computer program that he has trained to read texts in Yiddish (and other languages). So far, he has used the program to make the following Yiddish texts into searchable text:
- Abraham Sutzkever's Togbukh
- Leon Elbe's Yingele ringele
- Der groyser verterbukh
- Der Nister's Di mishpokhe mashber
- Sholem Aleichem's Tevye stories
- The complete works of Sholem Aleichem
What is OCR? What are the challenges to developing Yiddish OCR software?
Refoyl Finkel: OCR stands for "optical character recognition." It refers to any technique that converts an image of text into a file containing the characters found in that image. There are many OCR programs available—some free, some for purchase.
I have been developing my OCR program (let's just call it ROCR, for Refoyl's OCR) for many years. ROCR is not primed to recognize any particular alphabet. I must train it on documents in the alphabets I am interested in. I have used it for Roman-based alphabets (including Polish and Spanish) and Semitic alphabets (including Hebrew, Yiddish, and Geez).
One difficulty that occurs in many alphabets is associating marks with base characters. For example, in English, the letters i and j have dots that are separate from the character itself. Similarly, in Hebrew and Yiddish, the letter ה has two disconnected parts, and nekudes (diacritic marks) are always separate from the characters. It is a challenge to associate these marks with their characters.
ROCR tries to recognize characters by looking at the pattern of dark regions. It is likely to make the same mistakes that a beginning student makes, confusing (י / ו / ז / ן), (ס / ם), (מ / ט). ROCR is especially challenged in distinguishing commas from quote marks and the makef (־) from the dash (―).
Hebrew with nikud is actually harder than Yiddish, because any base character may be associated with any mark, leading to an explosion of characters that I must train ROCR to recognize.
Different books have different fonts, and I find that I must train ROCR for each font anew. It takes a few hours of training to reach an acceptable level of precision.
Yiddish of course has its own unique challenges. The double letters װ ,ױ, and ײ are indistinguishable from adjacent letters. I use a post-processing scheme to clean up the result of ROCR; part of that post-processing is to join those adjacent letters into single combined letters. I also use post-processing to correct some obvious errors, such as multiple hyphens in a row (due to small defects in the original image), final letter ם in the middle of a word, commas before a word (which should be quotes), and multiple commas after a word (which should be quotes).
How do you go about the process of teaching the program to read a particular text?
RF: I usually start ROCR in training mode with no letters at all in its data store. It can find rectangles around most of the letters on a page of scanned text, but it doesn't recognize any of the letters. I click on one of the letters and enter (in a text box) the appropriate character, using Unicode to represent the character. ROCR then adds that character to the database, associated with information it gleans from the letter. ROCR can handle text in any alphabet; I just need to be able somehow to enter the right character in the text box. I repeat this process for many of the characters on the page of text. I then have ROCR show me what characters it now recognizes on the page. ROCR places a red bar over every letter it cannot yet recognize, a green bar over a letter it has a good guess for, and no bar over a letter it thinks it knows with certainty. I usually address myself to the red-barred letters first; they are often ones that are unusual, so I haven't yet defined them, or they are hard to recognize, which often happens with small letters like yud. I can place as many examples of every letter as I wish in the database. Depending on how many different fonts the document uses, how good the scan is, and how consistent the document is (on some pages the ink might be light, on others dark), it can take from one to a few hours before I am satisfied with ROCR's accuracy.
I don't (yet) have a way to automatically train ROCR by using a known digitization of a given scan.
What kind of research does OCR enable?
RF: OCR allows for "corpus linguistics," which is a general term that encompasses many kinds of study:
- Discovering the range of meanings of a word by finding all places in which it is used.
- Discovering which adverbial complements a verb takes, or, more generally, discovering whether a verb is usually used in a reflexive construction, what prepositional phrases it typically has, and other similar matters.
- Seeing how frequently a word or idiom occurs, and relating that result to author and date of a text to find patterns.
- Seeing how spelling conventions change over time.
For Yiddish, OCR is important because it lets one quickly search for items (words or entire stories), and one can then take the resulting text and turn it into a useful form, such as a nicely printed document or an attractive website.
How successful has the software been? What kind of text does the OCR miss and why?
RF: Some letters, like lamed (לֹ), get very high accuracy. Some pairs are often confused, such as nun (נ) and gimel (ג). Post-processing can sometimes fix these errors automatically; there should be no final-nun (ן) letters in the middle of a word, for example, so I can automatically correct them to vov (ו).
But overall, it's hard to measure "success" of the software. The usual metric for OCR involves precision (how often the OCR gets the right character). I haven't made a formal study of ROCR’s precision; but depending on the clarity of the original document and the amount of training I do, I expect between 80 to 95 percent precision.
How many other existing OCR programs work for Yiddish? How does your OCR compare?
RF: I wish I knew. Assaf Urieli started working a few years ago with the Yiddish Book Center to make their digital collection searchable, and Yankl-Perets Blum just finished his master’s thesis on handling variant orthographical practices for OCR work. I don't know how close to realization Urieli's project is. Google clearly uses an OCR for Hebrew, but it's pretty poor for Yiddish, because it gets confused with a pasekh-tsvey-yudn (ײַ) and with the rofe over the fey (פֿ) and the veys (בֿ).
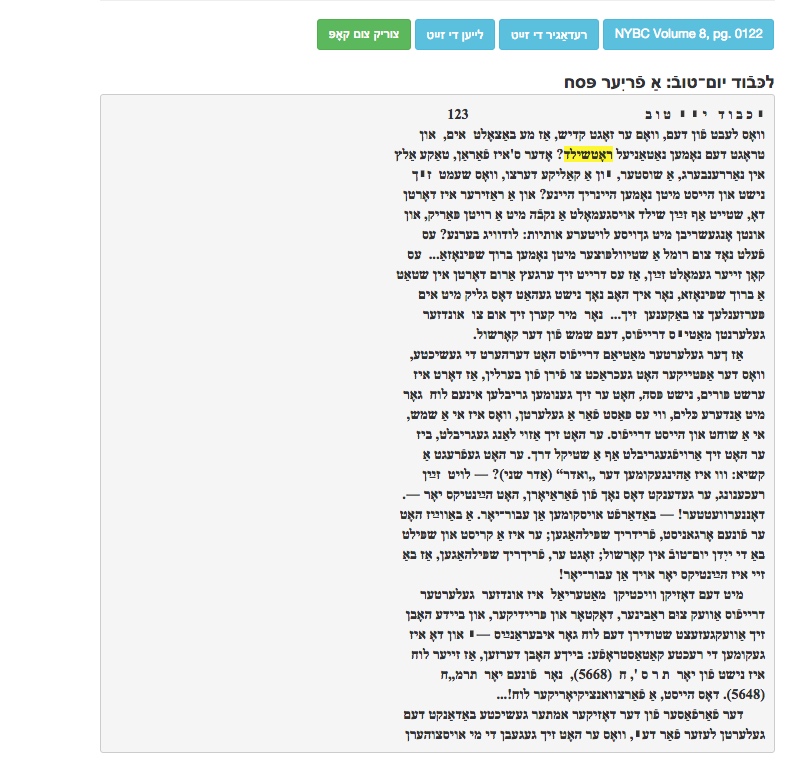
A screen shot of a sample search for “Rothschild” in Sholem Aleichem’s complete works.
How can other readers/users help with perfecting the system? Why might it be important that this be a collaborative project? How much progress have you made?
RF: I started the Sholem Aleichem project at the request of Robert Waife, a great-grandson of the author. This project is the first time I have set up a facility to crowdsource the proofreading step. (I have also been involved in a related project, the Suda On Line, since 1998.) Since setting up this facility in February, I have been making improvements in response to suggestions from the proofreaders and from my own experience in using it to proofread the texts. The importance of collaboration is that it lets others become invested in the text and it makes it possible to actually complete the proofreading, which I would certainly not be able to undertake alone. There is a status page which, as I write this, indicates that 5 percent of the total has been proofread at least once. At this rate, we should be finished by sometime in 2017. 1 1 Editor’s note: Since our interview with Refoyl Finkel in March, that number has jumped to 32 percent. Keep at it, helpful Yiddishists!
There are still some interesting problems to work out, such as how to deal with words that are emphasized by insertion of space between letters, whether to try to represent larger/smaller fonts, and whether to collect words that cross line and page boundaries into a single word.
What other digital Yiddish projects are you working on? What do you think are the most important digitization projects to Yiddish Studies today?
RF: I continue to develop my online Yiddish dictionary, principally by adding words that I discover while proofreading Sholem Aleichem. I use that dictionary as a guide to proofreaders, highlighting words that are missing from the dictionary to guide the proofreaders' attention, and even suggesting a replacement based on typical ROCR errors.
I have received a few requests to digitize (by which I mean conversion to text, not just saving a picture) the work of specific authors—in particular, Itzik Manger. I expect that I will apply the same techniques of crowdsourcing to such projects. I have played with, but in no way published: Hibru by Joseph Opatoshu, Y. L. Lazerov’s commentary on Leviticus, Yehoash's translation of Genesis, and Mirele Efros by Jacob Gordin.
How might OCR be useful for the study of Yiddish literature or research on the histories of Yiddish speaking communities?
RF: Any digitization with OCR of documents makes it easier to search through them, and even to discover a particular document among many. We see that benefit every day with search engines like Google. If we have digitized all issues of a journal, we can quickly find articles that deal with particular matters by searching for keywords. Even in the Sholem Aleichem stories one can find references to current events; just search for "Mendl Beylis" or "Dreyfus."
Might it be possible to create a “Google Books” of Yiddish language texts? Or is such a database still a ways away?
RF: All it takes is digitization. The Yiddish Book Center’s scans are a great first step. Unfortunately, ROCR needs to be trained for each text, so it will take a while to improve it to the point that we can just set it loose on the entire Yiddish Book Center corpus.

Refoyl Finkel
And finally, how did you personally get involved in the study of Yiddish? And what motivated you to get involved in OCR and other digital projects related to Yiddish? How does the study of Yiddish relate to your other academic pursuits?
RF: A proper answer would be very long. Let me just say my father's father, Morris Finkelstein, whom I never met, was a Yiddishist in Chicago. My father was fluent in Yiddish, but never used it at home. My earliest exposure to Yiddish was through recordings by Theodore Bikel (z’’l), Mark Olf, and Martha Schlamme. When my children were born, I decided to speak with them in Yiddish. I brought them to the yearly Yiddish vokh run by Yugntruf. I started a word list to assist in spelling correction, at the suggestion of Mr. Deutch (of the Forverts), 2 2 Editor’s note: Moyshe-Yuda Deutch is a Satmar Hasid who worked at the Forverts in the 1990s and early 2000s as a copyeditor. He is currently an editor at Der yid, a Satmar newspaper. and that led to all sorts of computer-based tools for transcribing and proofreading Yiddish. OCR was a natural extension.
My academic area is computer science. I teach in the general area of systems, which includes compiler construction and operating systems. At heart, it is a study of computer-based tools. So it's natural that I apply my abilities to build tools that I want, or that others want. I have also been interested all my life in languages. I have built various tools for linguists, too; in fact, I just coauthored a linguistics book based on one of those tools.
I am also working on OCR projects that are not in Yiddish: a dictionary of Haitian creole and a way to digitize a page of handwritten Geez. So my projects also take me outside of Yiddishland—even now I’m on sabbatical in Bandung, Indonesia!


