Mar 27, 2025

Homepage of the Corpus of Spoken Yiddish in Europe
INTRODUCTION
Isaac L. Bleaman is Assistant Professor of Linguistics and an affiliate of the Center for Jewish Studies at the University of California, Berkeley. He recently launched the Corpus of Spoken Yiddish in Europe, a digital language archive sourced from Holocaust survivor testimonies from the USC Shoah Foundation. Funded by a five-year CAREER Award from the National Science Foundation, the project is a resource for Yiddish linguistics, pedagogy, and language revitalization. Michelle Margolis, Norman E. Alexander Librarian for Jewish Studies at Columbia University, spoke to Dr. Bleaman about the history and ongoing development of the project.
MM: What made you think about using Holocaust testimonies to study Yiddish linguistics? Can you tell me more about what inspired the project and how it came to be?
ILB: I first learned about the Yiddish-language testimonies in the USC Shoah Foundation Visual History Archive (VHA) when I was an undergraduate at Stanford. One of my mentors, Zachary M. Baker, suggested that I listen to them to get a better understanding of spoken Yiddish from different dialect areas. The VHA contains almost 700 multi-hour testimony interviews in Yiddish, making it the single largest collection of recorded Yiddish conversation.
These testimonies proved to be an invaluable resource for my dissertation in sociolinguistics at NYU, which was a comparison of the spoken Yiddish of two separate communities in the New York area: Hasidim and Yiddishists. One of my research questions was whether the grammatical and phonetic differences that I was observing stemmed from the communities’ different ancestral dialects (Transcarpathian Yiddish among Hasidic speakers, versus a mix of other European dialects among Yiddishists), or if the communities have been diverging since their immigration to the United States. I analyzed several VHA interviews as a historical “baseline,” which supported my hypothesis that Hasidim and Yiddishists were undergoing linguistic divergence.
My colleague Chaya R. Nove also used VHA testimonies as a data source for her PhD research at the CUNY Graduate Center. After I joined the linguistics faculty at UC Berkeley and while Chaya was finishing her dissertation, we began working together to try to improve the accessibility of the Yiddish testimonies. For a number of reasons including the VHA’s subscription cost, none of the major organizations that teach Yiddish today (YIVO, the Yiddish Book Center, the Paris Yiddish Center, the Arbeter-ring, among others) has been able to provide VHA access to its students or instructors. Those who might have access through their university libraries (a map of VHA access sites is available online) still could not search through the Yiddish interviews, because none had been transcribed and many lacked basic metadata. [MM note: while the VHA has been adding transcriptions and more metadata to their testimonies in recent years, they have focused on testimonies in English and other large Western languages because they are using an outside vendor for transcription.]
Chaya and I approached the USC Shoah Foundation to see if we could transcribe their Yiddish testimonies and make the materials available to language researchers, teachers, and students. The organization accepted our proposal to develop the Corpus of Spoken Yiddish in Europe (CSYE) and provided us with a license for over 200 testimonies, which were chosen to achieve a balance across dialect areas. I received several faculty grants that allowed me to hire Chaya as a postdoc at UC Berkeley, where she worked as a corpus manager from 2021 to 2023. During that time I also received a major grant from the National Science Foundation to support the costs of corpus development and research for another five years. Chaya is now a Postdoctoral Research Associate in Linguistics at Brown, but she has remained involved in the project and is using the data for various research projects. We also co-authored an article describing the corpus, which was just published in the journal Language Documentation & Conservation.
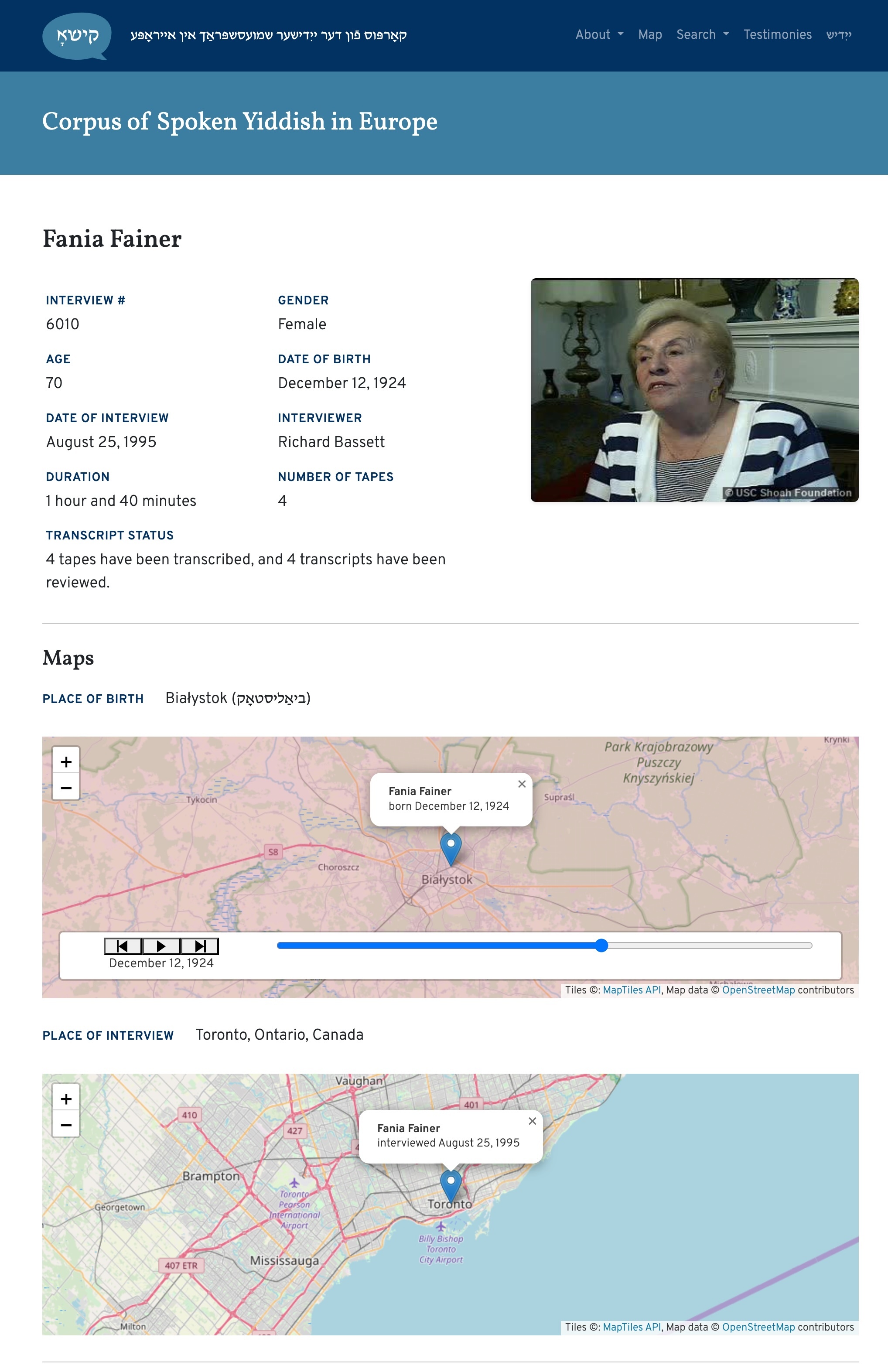
Testimony page for survivor Fania Fainer
MM: Wow, that sounds incredible — not only for Yiddish linguistics, but for Yiddish language learning and Holocaust research more broadly! Who is doing the transcription? How does it work?
ILB: Transcription is done by hand. We’ve hired several independent contractors who are fluent in Yiddish, as well as in other relevant co-territorial languages, and provided them with training in our transcription methodology. A list of our transcribers and reviewers is available on our website.
To streamline the transcription process, we use a machine learning tool to identify the voices of the two speakers in each recording (the survivor and interviewer) and mark off the time intervals when each person is talking. (My colleague Ronald Sprouse and I published a tutorial on this process, known as “speaker diarization,” along with interactive code.) Our transcribers then use ELAN, a popular transcription program for both audio and video, to transcribe these diarized files. We use a lightly adapted version of the YIVO transliteration standard, which facilitates searchability. Most Yiddish words are transcribed entirely in lowercase letters; we have separate conventions for transcribing the names of people, places, and organizations (using a single capital letter), as well as borrowings from other languages (all in uppercase) to make these easier to find.
The transcripts are separately reviewed by another team member. After they are checked over, I use my Python library yiddish to “detransliterate” the files into the Yiddish alphabet.
Transcription is very subtle and difficult work. We are always looking for fluent Yiddish speakers with knowledge of Standard Yiddish transliteration and a good ear for linguistic detail (we transcribe every “um” and “uh”!) who might want to get involved in the project.
As for the corpus website itself, I designed and built it in Jekyll. The website is hosted on GitHub and pulls in all of our metadata from a simple CSV file. Because the entire corpus is built as a static site, there is no backend database and almost no software dependencies for us to maintain on an ongoing basis.
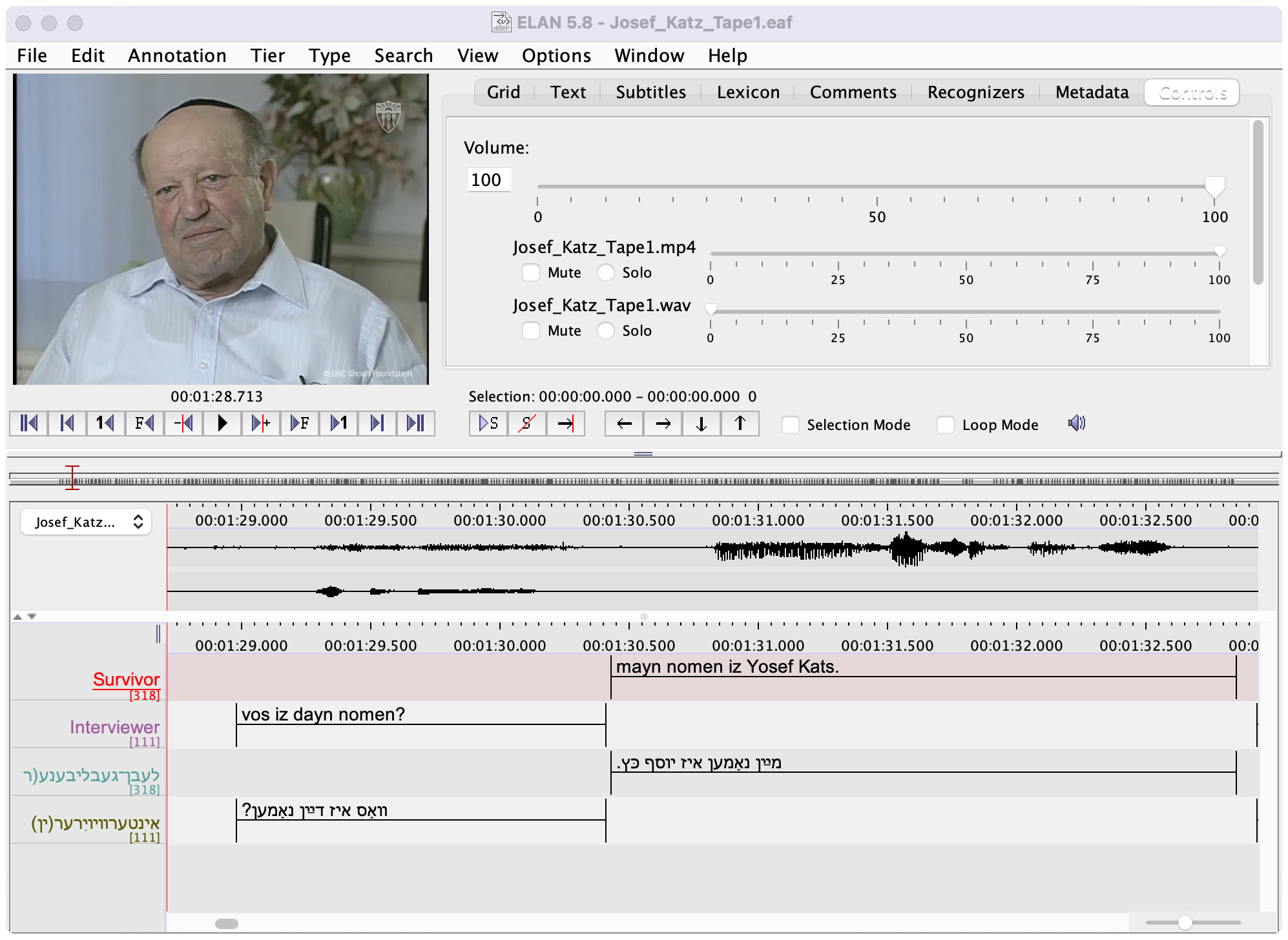
A transcribed and reviewed ELAN file from the testimony of survivor Josef Katz
MM: What is the intended audience of the project?
ILB: We have designed the corpus with a few different audiences in mind. First, there are linguists (like me and Chaya) who need data for research projects related to Yiddish dialectology, phonetics and phonology, syntax, semantics, sociolinguistic variation, and language change. There are also scholars in other areas of Yiddish Studies or Holocaust Studies who can benefit from the availability of transcribed interviews. For example, Hannah Pollin-Galay has worked with VHA testimonies to better understand how language choice affects the structure and themes of Holocaust survivor narratives, and how the Holocaust itself affected the lexicon of Yiddish. We’re hopeful that the CSYE will support continued scholarly engagement with the VHA’s Yiddish materials. Finally, language learners and teachers can use the CSYE to bring native Yiddish speech into the classroom. I’m particularly excited by the potential for the corpus to be used by heritage learners who want to revitalize their family’s local dialects.
Our website has a new section called CSYE Glosses, which are short articles containing interesting linguistic observations drawn from the corpus. I’ve been working on a set of articles specifically for language learners and teachers on topics related to pronunciation. The first one, about the pronunciation of ־ן nun at the end of Yiddish words, is already available online and includes short video clips from the testimonies embedded as examples.
The VHA contains several interviews with survivors who are well known in the world of Yiddish Studies, whose transcribed recordings are now available in the CSYE. These include the lexicographer and scholar of Lithuanian Yiddish Khatskl Lemkhen and memoirist Masha Rolnikaite. Yiddish cultural activist Fania Brancovskaya, whose language is described briefly in a Glosses article by Ben Sadock, ends her four-and-a-half-hour interview with a tour of Vilnius. For those who weren’t able to join her on one of her famous walking tours before her passing last September, this is a real treasure.
MM: Many projects hold off on publishing their data right away because they plan to publish their findings. But at the same time, making the data available allows others to do different kinds of research with the data. What are your views/policies on this?
ILB: Our policy is to publish all materials online as soon as they are transcribed. For this reason, the corpus is growing nearly every day. Originally we planned to wait for all transcripts to be checked over by an independent reviewer before putting them online — which is still an important long-term goal — but we found that this was a bottleneck and we wanted to provide access to the content immediately. The search page allows users to limit their results to reviewed transcripts if they wish.
Users of the CSYE agree to abide by our Terms of Use, as well as the Terms of Use of the USC Shoah Foundation. Both of these are documented in our User Guide, which will soon be updated with additional instructions and tips on how to navigate the corpus. Information on how to cite the CSYE and individual VHA testimonies is provided at the bottom of each survivor’s page.
MM: How does one access the transcripts?
ILB: The transcripts are available on our website as subtitles embedded in our video players, in searchable transcript tables on each survivor’s page, and in a public GitHub repository. The USC Shoah Foundation has also expressed interest in embedding them into the media players on the VHA website.
MM: As curator for Jewish Studies at Columbia, whose collection includes the Language and Culture Archive of Ashkenazic Jewry (LCAAJ), I’m obviously interested in overlaps between your project and the LCAAJ. Have you intentionally added LCAAJ references?
ILB: Absolutely! Visitors to the corpus website can already find links to the LCAAJ in an optional “layer” on our main map page. This is especially useful for those who want to study (or acquire!) the dialect of a specific region and are looking for information beyond what can be found in the CSYE.
In many ways, the LCAAJ and CSYE are complementary datasets that serve different purposes. The LCAAJ was designed for dialectological research, and so its recordings follow a lengthy questionnaire with very specific questions about linguistic and cultural items (e.g., What’s the name for the end piece of a loaf of bread?). The LCAAJ recordings and fieldnotes are immensely useful for mapping the presence or absence of such categorical features across dialects. But they are less informative for understanding aspects of language that are more variable within dialect regions or even within the speech of individuals. The CSYE fills this gap because it consists exclusively of spontaneous conversation from oral history interviews.
This point is nicely illustrated in Glosses articles that our transcriber Ben Sadock recently wrote about variation in the use of nit vs. nisht as a negation marker, and related forms like gornit vs. gornisht “nothing.” If we were to produce a dialect map of gornit vs. gornisht by asking speakers to translate a single sentence containing the word “nothing” — similar to the methodology of the LCAAJ — we’d be missing out on the fact that many individuals actually produce both forms. Conversational recordings allow us to systematically analyze these kinds of variable language features. (Users can produce their own maps comparing the use of related word forms, like gornit vs. gornisht, on our “word maps” page.)
The LCAAJ interviews were recorded between 1959 and 1972 on audio tapes. By contrast, the VHA testimonies were collected much later (in the late 1990s and early 2000s) and recorded on video cassettes. The quality of the VHA recordings makes them much better suited for phonetic analysis. Also, video recordings make it possible to investigate multimodal aspects of communication, such as the use of gestures.
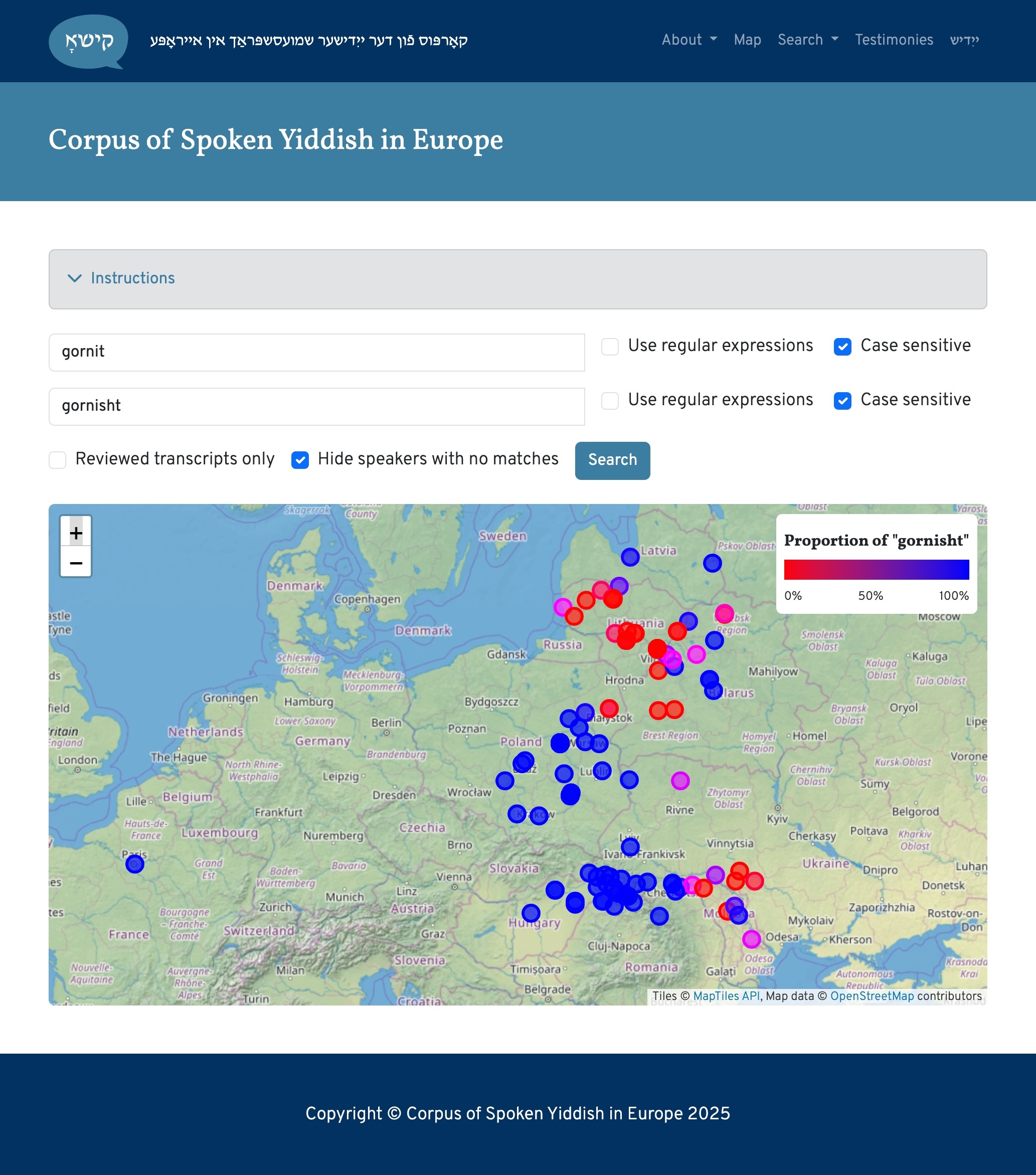
Map showing the distribution of gornit (red) vs. gornisht (blue) in the CSYE
MM: This really sounds like an incredible resource, one that will benefit many people in multiple fields. What is the timeline for the project?
ILB: My grant from the NSF currently runs through 2027, but I hope that the project will continue to develop and grow well beyond that. I’d love to hear from users who might have ideas for collaboration, or from other archives that are willing to share and publish their digitized Yiddish recordings. And of course, I’m always looking to improve the quality and accuracy of our transcriptions. Information on how to submit corrections to the corpus is available on the CSYE contact page.



